前言
实现 《谁说菜鸟不会数据分析》 代码
数据处理
数据清洗
数据排序
按照一定顺序排序,以便研究者通过浏览数据发现一些明显的特征、规律或趋势,找到解决问题的线索。有助于对数据检查纠错,以及为重新归类或分组等提供方便
|
|
|
|
| 用户ID | 性别 | 年龄 | |
|---|---|---|---|
| 0 | 100000 | 男 | 52 |
| 1 | 100001 | 男 | 23 |
| 2 | 100002 | 男 | 30 |
| 3 | 100006 | 男 | 28 |
| 4 | 100010 | 男 | 28 |
|
|
| 用户ID | 性别 | 年龄 | |
|---|---|---|---|
| 6 | 100012 | 男 | 21 |
| 1 | 100001 | 男 | 23 |
| 7 | 100013 | 男 | 24 |
| 9 | 100016 | 男 | 26 |
| 5 | 100011 | 男 | 27 |
| 3 | 100006 | 男 | 28 |
| 4 | 100010 | 男 | 28 |
| 2 | 100002 | 男 | 30 |
| 10 | 100017 | 女 | 30 |
| 8 | 100015 | 男 | 33 |
| 0 | 100000 | 男 | 52 |
重复数据处理
重复数据查找
|
|
| ID | 姓名 | 性别 | |
|---|---|---|---|
| 0 | 1 | 刘一 | 男 |
| 1 | 1 | 刘一 | 男 |
| 2 | 3 | 张三 | 男 |
| 3 | 4 | 李四 | 女 |
| 4 | 5 | 王五 | 女 |
| 5 | 6 | 赵六 | 男 |
| 6 | 7 | 孙七 | 女 |
| 7 | 8 | 周八 | 女 |
| 8 | 9 | 吴九 | 男 |
| 9 | 10 | 郑十 | 男 |
|
|
0 False
1 True
2 False
3 False
4 False
5 False
6 False
7 False
8 False
9 False
dtype: bool
|
|
0 False
1 True
2 True
3 False
4 True
5 True
6 True
7 True
8 True
9 True
dtype: bool
重复数据删除
|
|
| ID | 姓名 | 性别 | |
|---|---|---|---|
| 0 | 1 | 刘一 | 男 |
| 2 | 3 | 张三 | 男 |
| 3 | 4 | 李四 | 女 |
| 4 | 5 | 王五 | 女 |
| 5 | 6 | 赵六 | 男 |
| 6 | 7 | 孙七 | 女 |
| 7 | 8 | 周八 | 女 |
| 8 | 9 | 吴九 | 男 |
| 9 | 10 | 郑十 | 男 |
缺失数据处理
处理方法:
- 填充,用平均值等方法进行填充
- 删除有缺失值的行,如果数据量较小不适合
- 不处理
数据补齐
|
|
| ID | 姓名 | 消费 | |
|---|---|---|---|
| 0 | 1 | 刘一 | 256.0 |
| 1 | 2 | 陈二 | NaN |
| 2 | 3 | 张三 | 282.0 |
| 3 | 4 | 李四 | 245.0 |
| 4 | 5 | 王五 | 162.0 |
| 5 | 6 | 赵六 | 295.0 |
| 6 | 7 | 孙七 | 173.0 |
| 7 | 8 | 周八 | 197.0 |
| 8 | 9 | 吴九 | 236.0 |
| 9 | 10 | 郑十 | 311.0 |
|
|
| ID | 姓名 | 消费 | |
|---|---|---|---|
| 0 | 1 | 刘一 | 256.000000 |
| 1 | 2 | 陈二 | 239.666667 |
| 2 | 3 | 张三 | 282.000000 |
| 3 | 4 | 李四 | 245.000000 |
| 4 | 5 | 王五 | 162.000000 |
| 5 | 6 | 赵六 | 295.000000 |
| 6 | 7 | 孙七 | 173.000000 |
| 7 | 8 | 周八 | 197.000000 |
| 8 | 9 | 吴九 | 236.000000 |
| 9 | 10 | 郑十 | 311.000000 |
删除缺失值
|
|
| ID | 姓名 | 消费 | |
|---|---|---|---|
| 0 | 1 | 刘一 | 256.0 |
| 2 | 3 | 张三 | 282.0 |
| 3 | 4 | 李四 | 245.0 |
| 4 | 5 | 王五 | 162.0 |
| 5 | 6 | 赵六 | 295.0 |
| 6 | 7 | 孙七 | 173.0 |
| 7 | 8 | 周八 | 197.0 |
| 8 | 9 | 吴九 | 236.0 |
| 9 | 10 | 郑十 | 311.0 |
空格数据处理
空格数据是指字符串型数据的前面或后面存在空格
|
|
| id | name | |
|---|---|---|
| 0 | 1 | KEN |
| 1 | 2 | JIMI |
| 2 | 3 | John |
|
|
0 KEN
1 JIMI
2 John
Name: name, dtype: object
数据转换
数值转字符串
|
|
| ID | 姓名 | 消费 | 电话号码 | |
|---|---|---|---|---|
| 0 | 1 | 刘一 | 256.1 | 166547114238 |
| 1 | 2 | 陈二 | 239.5 | 166423353436 |
| 2 | 3 | 张三 | 282.6 | 166556915853 |
| 3 | 4 | 李四 | 245.8 | 166434728749 |
| 4 | 5 | 王五 | 162.3 | 166544742252 |
| 5 | 6 | 赵六 | 295.3 | 166827395761 |
| 6 | 7 | 孙七 | 173.6 | 166917847616 |
| 7 | 8 | 周八 | 197.9 | 166528757061 |
| 8 | 9 | 吴九 | 236.2 | 166809774605 |
| 9 | 10 | 郑十 | 311.1 | 166434676621 |
|
|
ID int64
姓名 object
消费 float64
电话号码 int64
dtype: object
|
|
dtype('int64')
|
|
dtype('O')
字符串转数值
|
|
dtype('float64')
字符串转时间
时间转换
|
|
| 电话 | 注册时间 | 是否微信 | |
|---|---|---|---|
| 0 | 166412894295 | 2011/1/1 | 否 |
| 1 | 135416795207 | 2012/2/3 | 否 |
| 2 | 177423353436 | 2013/3/2 | 是 |
| 3 | 189424978309 | 2014/4/11 | 是 |
| 4 | 134450811715 | 2015/5/18 | 否 |
| 5 | 137450811771 | 2016/6/12 | 否 |
| 6 | 173450811789 | 2017/7/15 | 是 |
| 7 | 188450811792 | 2018/8/17 | 是 |
| 8 | 168450811840 | 2019/9/16 | 是 |
|
|
dtype('O')
|
|
| 电话 | 注册时间 | 是否微信 | 时间 | |
|---|---|---|---|---|
| 0 | 166412894295 | 2011/1/1 | 否 | 2011-01-01 |
| 1 | 135416795207 | 2012/2/3 | 否 | 2012-02-03 |
| 2 | 177423353436 | 2013/3/2 | 是 | 2013-03-02 |
| 3 | 189424978309 | 2014/4/11 | 是 | 2014-04-11 |
| 4 | 134450811715 | 2015/5/18 | 否 | 2015-05-18 |
|
|
dtype('<M8[ns]')
时间格式化
|
|
| 电话 | 注册时间 | 是否微信 | 时间 | 年月 | |
|---|---|---|---|---|---|
| 0 | 166412894295 | 2011/1/1 | 否 | 2011-01-01 | 2011-01 |
| 1 | 135416795207 | 2012/2/3 | 否 | 2012-02-03 | 2012-02 |
| 2 | 177423353436 | 2013/3/2 | 是 | 2013-03-02 | 2013-03 |
| 3 | 189424978309 | 2014/4/11 | 是 | 2014-04-11 | 2014-04 |
| 4 | 134450811715 | 2015/5/18 | 否 | 2015-05-18 | 2015-05 |
数据抽取
字段分拆
按照位置分拆
|
|
| tel | |
|---|---|
| 0 | 18922254812 |
| 1 | 13522255003 |
| 2 | 13422259938 |
| 3 | 18822256753 |
| 4 | 18922253721 |
| 5 | 13422259313 |
| 6 | 13822254373 |
| 7 | 13322252452 |
| 8 | 18922257681 |
|
|
| tel | |
|---|---|
| 0 | 18922254812 |
| 1 | 13522255003 |
| 2 | 13422259938 |
| 3 | 18822256753 |
| 4 | 18922253721 |
|
|
| tel | bands | areas | nums | |
|---|---|---|---|---|
| 0 | 18922254812 | 189 | 2225 | 4812 |
| 1 | 13522255003 | 135 | 2225 | 5003 |
| 2 | 13422259938 | 134 | 2225 | 9938 |
| 3 | 18822256753 | 188 | 2225 | 6753 |
| 4 | 18922253721 | 189 | 2225 | 3721 |
按照分隔符拆分
|
|
| name | |
|---|---|
| 0 | Apple iPad mini |
| 1 | 华为 MediaPad 7Vogue |
| 2 | 昂达(ONDA) V975四核 |
| 3 | 华为(HUAWEI) 荣耀X1 |
| 4 | 酷比魔方(CUBE) TALK7X四核 |
| 5 | 惠普(HP) Slate 7 |
| 6 | 酷比魔方(ACUBE) TALK97 |
| 7 | 三星(SAMSUNG) GALAXY NotePro |
|
|
| band | name | |
|---|---|---|
| 0 | Apple | iPad mini |
| 1 | 华为 | MediaPad 7Vogue |
| 2 | 昂达(ONDA) | V975四核 |
| 3 | 华为(HUAWEI) | 荣耀X1 |
| 4 | 酷比魔方(CUBE) | TALK7X四核 |
时间属性抽取
|
|
| 电话 | 注册时间 | 是否微信 | |
|---|---|---|---|
| 0 | 166412894295 | 2011/1/1 12:13:24 | 否 |
| 1 | 135416795207 | 2012/2/3 1:15:38 | 否 |
| 2 | 177423353436 | 2013/3/2 13:54:55 | 是 |
| 3 | 189424978309 | 2014/4/11 11:00:03 | 是 |
| 4 | 134450811715 | 2015/5/18 10:02:23 | 否 |
|
|
|
|
| 电话 | 注册时间 | 是否微信 | 时间 | 时间.年 | |
|---|---|---|---|---|---|
| 0 | 166412894295 | 2011/1/1 12:13:24 | 否 | 2011-01-01 12:13:24 | 2011 |
| 1 | 135416795207 | 2012/2/3 1:15:38 | 否 | 2012-02-03 01:15:38 | 2012 |
| 2 | 177423353436 | 2013/3/2 13:54:55 | 是 | 2013-03-02 13:54:55 | 2013 |
| 3 | 189424978309 | 2014/4/11 11:00:03 | 是 | 2014-04-11 11:00:03 | 2014 |
| 4 | 134450811715 | 2015/5/18 10:02:23 | 否 | 2015-05-18 10:02:23 | 2015 |
记录抽取
|
|
| id | comments | title | ptime | |
|---|---|---|---|---|
| 0 | 1197453 | 10071 | 华为(HUAWEI) 荣耀平板 | 2015-05-26 |
| 1 | 1192330 | 16879 | Apple iPad平板 | 2012-01-26 |
| 2 | 1225995 | 2218 | 小米(MI)7.9英寸平板 | 2013-06-16 |
| 3 | 1308557 | 12605 | Apple IPad mini平板 | 2013-05-26 |
| 4 | 1185287 | 11836 | 微软(Microsoft) Surface Pro 3 | 2016-08-21 |
关键词抽取
|
|
| id | comments | title | ptime | |
|---|---|---|---|---|
| 7 | 1150612 | 5857 | 台电(Teclast) P98 | 2015-05-14 |
| 8 | 1285329 | 2482 | 台电(Teclast)X98 Air | 2015-08-21 |
空值抽取
|
|
| id | comments | title | ptime | |
|---|---|---|---|---|
| 5 | 1197789 | 2084 | NaN | 2015-03-03 |
数值范围抽取
|
|
| id | comments | title | ptime | |
|---|---|---|---|---|
| 0 | 1197453 | 10071 | 华为(HUAWEI) 荣耀平板 | 2015-05-26 |
| 1 | 1192330 | 16879 | Apple iPad平板 | 2012-01-26 |
| 3 | 1308557 | 12605 | Apple IPad mini平板 | 2013-05-26 |
| 4 | 1185287 | 11836 | 微软(Microsoft) Surface Pro 3 | 2016-08-21 |
| 6 | 996957 | 11123 | Apple iPad Air | 2015-02-10 |
|
|
| id | comments | title | ptime | |
|---|---|---|---|---|
| 2 | 1225995 | 2218 | 小米(MI)7.9英寸平板 | 2013-06-16 |
| 5 | 1197789 | 2084 | NaN | 2015-03-03 |
| 7 | 1150612 | 5857 | 台电(Teclast) P98 | 2015-05-14 |
| 8 | 1285329 | 2482 | 台电(Teclast)X98 Air | 2015-08-21 |
组合条件抽取
|
|
| id | comments | title | ptime | |
|---|---|---|---|---|
| 2 | 1225995 | 2218 | 小米(MI)7.9英寸平板 | 2013-06-16 |
| 5 | 1197789 | 2084 | NaN | 2015-03-03 |
| 7 | 1150612 | 5857 | 台电(Teclast) P98 | 2015-05-14 |
| 8 | 1285329 | 2482 | 台电(Teclast)X98 Air | 2015-08-21 |
时间范围抽取
|
|
dtype('O')
|
|
|
|
| id | comments | title | ptime | |
|---|---|---|---|---|
| 0 | 1197453 | 10071 | 华为(HUAWEI) 荣耀平板 | 2015-05-26 |
| 5 | 1197789 | 2084 | NaN | 2015-03-03 |
| 6 | 996957 | 11123 | Apple iPad Air | 2015-02-10 |
| 7 | 1150612 | 5857 | 台电(Teclast) P98 | 2015-05-14 |
| 8 | 1285329 | 2482 | 台电(Teclast)X98 Air | 2015-08-21 |
随机抽样
按个数抽样
|
|
| ID | 姓名 | 消费 | |
|---|---|---|---|
| 0 | 1 | 刘一 | 256 |
| 1 | 2 | 陈二 | 239 |
| 2 | 3 | 张三 | 282 |
| 3 | 4 | 李四 | 245 |
| 4 | 5 | 王五 | 162 |
|
|
| ID | 姓名 | 消费 | |
|---|---|---|---|
| 0 | 1 | 刘一 | 256 |
| 6 | 7 | 孙七 | 173 |
| 1 | 2 | 陈二 | 239 |
按照百分比抽样
|
|
| ID | 姓名 | 消费 | |
|---|---|---|---|
| 2 | 3 | 张三 | 282 |
| 1 | 2 | 陈二 | 239 |
是否放回抽样
|
|
| ID | 姓名 | 消费 | |
|---|---|---|---|
| 7 | 8 | 周八 | 197 |
| 4 | 5 | 王五 | 162 |
| 1 | 2 | 陈二 | 239 |
数据合并
记录合并
|
|
| id | comments | title | |
|---|---|---|---|
| 0 | 1235465 | 3256 | 台电(Teclast)X98 Air Ⅱ |
| 1 | 1312660 | 342 | 台电(Teclast)X10HD 3G |
| 2 | 1192758 | 1725 | 台电(Teclast)P98 Air |
| 3 | 1312671 | 279 | 台电(Teclast)X89 |
| 4 | 1094550 | 2563 | 台电(Teclast) P19HD |
|
|
| id | comments | title | |
|---|---|---|---|
| 0 | 1134006 | 13231 | 小米(MI) MIX |
| 1 | 1192330 | 6879 | 小米(MI) MIX 2 |
| 2 | 1225995 | 2218 | 小米(MI) MAX |
| 3 | 1225988 | 1336 | 小米(MI) MAX 2 |
| 4 | 1284247 | 578 | 小米(MI) 7 |
|
|
| id | comments | title | |
|---|---|---|---|
| 0 | 996961 | 62014 | Apple iPad Air |
| 1 | 996967 | 59503 | Apple iPad mini |
| 2 | 1246836 | 8791 | Apple iPhone 7 |
| 3 | 996964 | 9332 | Apple iPhone X |
| 4 | 1250967 | 4932 | Apple iPad Air 2 |
|
|
| id | comments | title | |
|---|---|---|---|
| 0 | 1235465 | 3256 | 台电(Teclast)X98 Air Ⅱ |
| 1 | 1312660 | 342 | 台电(Teclast)X10HD 3G |
| 2 | 1192758 | 1725 | 台电(Teclast)P98 Air |
| 3 | 1312671 | 279 | 台电(Teclast)X89 |
| 4 | 1094550 | 2563 | 台电(Teclast) P19HD |
| 5 | 1327452 | 207 | 台电(Teclast)P80 3G |
| 0 | 1134006 | 13231 | 小米(MI) MIX |
| 1 | 1192330 | 6879 | 小米(MI) MIX 2 |
| 2 | 1225995 | 2218 | 小米(MI) MAX |
| 3 | 1225988 | 1336 | 小米(MI) MAX 2 |
| 4 | 1284247 | 578 | 小米(MI) 7 |
| 0 | 996961 | 62014 | Apple iPad Air |
| 1 | 996967 | 59503 | Apple iPad mini |
| 2 | 1246836 | 8791 | Apple iPhone 7 |
| 3 | 996964 | 9332 | Apple iPhone X |
| 4 | 1250967 | 4932 | Apple iPad Air 2 |
字段合并
|
|
| band | area | num | |
|---|---|---|---|
| 0 | 189 | 2225 | 4812 |
| 1 | 135 | 2225 | 5003 |
| 2 | 134 | 2225 | 9938 |
| 3 | 188 | 2225 | 6753 |
| 4 | 189 | 2225 | 3721 |
|
|
| band | area | num | tel | |
|---|---|---|---|---|
| 0 | 189 | 2225 | 4812 | 18922254812 |
| 1 | 135 | 2225 | 5003 | 13522255003 |
| 2 | 134 | 2225 | 9938 | 13422259938 |
| 3 | 188 | 2225 | 6753 | 18822256753 |
| 4 | 189 | 2225 | 3721 | 18922253721 |
字段匹配
|
|
| id | comments | title | |
|---|---|---|---|
| 0 | 996955 | 2412 | Apple iPad Air |
| 1 | 1251208 | 2061 | Apple iPad Air 2 |
| 2 | 1197453 | 10071 | 华为(HUAWEI) 荣耀平板 |
| 3 | 1192330 | 6879 | 小米(MI) 平板 |
| 4 | 1225995 | 2218 | 小米(MI) MAX 2 |
|
|
| id | oldPrice | nowPrice | |
|---|---|---|---|
| 0 | 996955 | 3099 | 4299 |
| 1 | 1251208 | 4288 | 4289 |
| 2 | 1197453 | 799 | 1000 |
| 3 | 1192330 | 1699 | 1799 |
| 4 | 1225995 | 1299 | 1599 |
|
|
| id | comments | title | oldPrice | nowPrice | |
|---|---|---|---|---|---|
| 0 | 996955 | 2412 | Apple iPad Air | 3099 | 4299 |
| 1 | 1251208 | 2061 | Apple iPad Air 2 | 4288 | 4289 |
| 2 | 1197453 | 10071 | 华为(HUAWEI) 荣耀平板 | 799 | 1000 |
| 3 | 1192330 | 6879 | 小米(MI) 平板 | 1699 | 1799 |
| 4 | 1225995 | 2218 | 小米(MI) MAX 2 | 1299 | 1599 |
| 5 | 1308557 | 1605 | 华为(HUAWEI) Mate 2 | 999 | 1099 |
| 6 | 1185287 | 836 | 微软(Microsoft) Surface Pro 3 | 7388 | 7588 |
| 7 | 1197789 | 2084 | 小米(MI) MAX 1 | 1299 | 1500 |
| 8 | 996957 | 11123 | Apple iPad Air 2 | 2788 | 2899 |
| 9 | 1150612 | 5857 | 台电(Teclast) P98 | 999 | 1499 |
|
|
| id | comments | title | oldPrice | nowPrice | |
|---|---|---|---|---|---|
| 0 | 996955 | 2412 | Apple iPad Air | 3099.0 | 4299 |
| 1 | 1251208 | 2061 | Apple iPad Air 2 | 4288.0 | 4289 |
| 2 | 1197453 | 10071 | 华为(HUAWEI) 荣耀平板 | 799.0 | 1000 |
| 3 | 1192330 | 6879 | 小米(MI) 平板 | 1699.0 | 1799 |
| 4 | 1225995 | 2218 | 小米(MI) MAX 2 | 1299.0 | 1599 |
| 5 | 1308557 | 1605 | 华为(HUAWEI) Mate 2 | 999.0 | 1099 |
| 6 | 1185287 | 836 | 微软(Microsoft) Surface Pro 3 | 7388.0 | 7588 |
| 7 | 1197789 | 2084 | 小米(MI) MAX 1 | 1299.0 | 1500 |
| 8 | 996957 | 11123 | Apple iPad Air 2 | 2788.0 | 2899 |
| 9 | 1150612 | 5857 | 台电(Teclast) P98 | 999.0 | 1499 |
| 10 | 0 | 0 | 左边才有的 | NaN | NaN |
|
|
| id | comments | title | oldPrice | nowPrice | |
|---|---|---|---|---|---|
| 0 | 996955 | 2412.0 | Apple iPad Air | 3099 | 4299 |
| 1 | 1251208 | 2061.0 | Apple iPad Air 2 | 4288 | 4289 |
| 2 | 1197453 | 10071.0 | 华为(HUAWEI) 荣耀平板 | 799 | 1000 |
| 3 | 1192330 | 6879.0 | 小米(MI) 平板 | 1699 | 1799 |
| 4 | 1225995 | 2218.0 | 小米(MI) MAX 2 | 1299 | 1599 |
| 5 | 1308557 | 1605.0 | 华为(HUAWEI) Mate 2 | 999 | 1099 |
| 6 | 1185287 | 836.0 | 微软(Microsoft) Surface Pro 3 | 7388 | 7588 |
| 7 | 1197789 | 2084.0 | 小米(MI) MAX 1 | 1299 | 1500 |
| 8 | 996957 | 11123.0 | Apple iPad Air 2 | 2788 | 2899 |
| 9 | 1150612 | 5857.0 | 台电(Teclast) P98 | 999 | 1499 |
| 10 | 1 | NaN | NaN | 1 | 右边才有的 |
|
|
| id | comments | title | oldPrice | nowPrice | |
|---|---|---|---|---|---|
| 0 | 996955 | 2412.0 | Apple iPad Air | 3099.0 | 4299 |
| 1 | 1251208 | 2061.0 | Apple iPad Air 2 | 4288.0 | 4289 |
| 2 | 1197453 | 10071.0 | 华为(HUAWEI) 荣耀平板 | 799.0 | 1000 |
| 3 | 1192330 | 6879.0 | 小米(MI) 平板 | 1699.0 | 1799 |
| 4 | 1225995 | 2218.0 | 小米(MI) MAX 2 | 1299.0 | 1599 |
| 5 | 1308557 | 1605.0 | 华为(HUAWEI) Mate 2 | 999.0 | 1099 |
| 6 | 1185287 | 836.0 | 微软(Microsoft) Surface Pro 3 | 7388.0 | 7588 |
| 7 | 1197789 | 2084.0 | 小米(MI) MAX 1 | 1299.0 | 1500 |
| 8 | 996957 | 11123.0 | Apple iPad Air 2 | 2788.0 | 2899 |
| 9 | 1150612 | 5857.0 | 台电(Teclast) P98 | 999.0 | 1499 |
| 10 | 0 | 0.0 | 左边才有的 | NaN | NaN |
| 11 | 1 | NaN | NaN | 1.0 | 右边才有的 |
数据计算
简单计算
|
|
| name | price | num | |
|---|---|---|---|
| 0 | A | 6058 | 408 |
| 1 | B | 1322 | 653 |
| 2 | C | 7403 | 400 |
| 3 | D | 4911 | 487 |
| 4 | E | 3320 | 56 |
|
|
| name | price | num | total | |
|---|---|---|---|---|
| 0 | A | 6058 | 408 | 2471664 |
| 1 | B | 1322 | 653 | 863266 |
| 2 | C | 7403 | 400 | 2961200 |
| 3 | D | 4911 | 487 | 2391657 |
| 4 | E | 3320 | 56 | 185920 |
时间计算
|
|
| 电话 | 注册时间 | 是否微信 | |
|---|---|---|---|
| 0 | 166412894295 | 2011/1/1 | 否 |
| 1 | 135416795207 | 2012/2/3 | 否 |
| 2 | 177423353436 | 2013/3/2 | 是 |
| 3 | 189424978309 | 2014/4/11 | 是 |
| 4 | 134450811715 | 2015/5/18 | 否 |
|
|
| 电话 | 注册时间 | 是否微信 | 时间 | |
|---|---|---|---|---|
| 0 | 166412894295 | 2011/1/1 | 否 | 2011-01-01 |
| 1 | 135416795207 | 2012/2/3 | 否 | 2012-02-03 |
| 2 | 177423353436 | 2013/3/2 | 是 | 2013-03-02 |
| 3 | 189424978309 | 2014/4/11 | 是 | 2014-04-11 |
| 4 | 134450811715 | 2015/5/18 | 否 | 2015-05-18 |
|
|
| 电话 | 注册时间 | 是否微信 | 时间 | 注册天数 | |
|---|---|---|---|---|---|
| 0 | 166412894295 | 2011/1/1 | 否 | 2011-01-01 | 3188 days 18:19:05.434942 |
| 1 | 135416795207 | 2012/2/3 | 否 | 2012-02-03 | 2790 days 18:19:05.434942 |
| 2 | 177423353436 | 2013/3/2 | 是 | 2013-03-02 | 2397 days 18:19:05.434942 |
| 3 | 189424978309 | 2014/4/11 | 是 | 2014-04-11 | 1992 days 18:19:05.434942 |
| 4 | 134450811715 | 2015/5/18 | 否 | 2015-05-18 | 1590 days 18:19:05.434942 |
|
|
| 电话 | 注册时间 | 是否微信 | 时间 | 注册天数 | |
|---|---|---|---|---|---|
| 0 | 166412894295 | 2011/1/1 | 否 | 2011-01-01 | 3188 |
| 1 | 135416795207 | 2012/2/3 | 否 | 2012-02-03 | 2790 |
| 2 | 177423353436 | 2013/3/2 | 是 | 2013-03-02 | 2397 |
| 3 | 189424978309 | 2014/4/11 | 是 | 2014-04-11 | 1992 |
| 4 | 134450811715 | 2015/5/18 | 否 | 2015-05-18 | 1590 |
数据标准化
数据标准化是指对数据按照比例进行缩放,使之落入特定区域,数据标准化的作用就是消除单位量纲的影响,方便进行不同变量间的对比分析
0-1标准化:
x’ = (x - min) / (max -min)
|
|
| ID | 姓名 | 消费 | |
|---|---|---|---|
| 0 | 1 | 刘一 | 256 |
| 1 | 2 | 陈二 | 239 |
| 2 | 3 | 张三 | 282 |
| 3 | 4 | 李四 | 245 |
| 4 | 5 | 王五 | 162 |
|
|
| ID | 姓名 | 消费 | 消费标准化 | |
|---|---|---|---|---|
| 0 | 1 | 刘一 | 256 | 0.630872 |
| 1 | 2 | 陈二 | 239 | 0.516779 |
| 2 | 3 | 张三 | 282 | 0.805369 |
| 3 | 4 | 李四 | 245 | 0.557047 |
| 4 | 5 | 王五 | 162 | 0.000000 |
数据分组
|
|
| tel | cost | |
|---|---|---|
| 0 | 166424556600 | 2.0 |
| 1 | 166424557199 | 5.0 |
| 2 | 166424561768 | 75.3 |
| 3 | 166424569696 | 20.0 |
| 4 | 166424569924 | 97.3 |
分组的数组
|
|
2.0
|
|
100.0
|
|
| tel | cost | cut | |
|---|---|---|---|
| 0 | 166424556600 | 2.0 | (0, 20] |
| 1 | 166424557199 | 5.0 | (0, 20] |
| 2 | 166424561768 | 75.3 | (60, 80] |
| 3 | 166424569696 | 20.0 | (0, 20] |
| 4 | 166424569924 | 97.3 | (80, 100] |
区间的闭合
默认是使用 左开右闭 的
right = True 表示 左开右闭
right = False 表示 左闭右开
|
|
| tel | cost | cut | |
|---|---|---|---|
| 0 | 166424556600 | 2.0 | [0, 20) |
| 1 | 166424557199 | 5.0 | [0, 20) |
| 2 | 166424561768 | 75.3 | [60, 80) |
| 3 | 166424569696 | 20.0 | [20, 40) |
| 4 | 166424569924 | 97.3 | [80, 100) |
自定义标签
|
|
| tel | cost | cut | |
|---|---|---|---|
| 0 | 166424556600 | 2.0 | 0-20 |
| 1 | 166424557199 | 5.0 | 0-20 |
| 2 | 166424561768 | 75.3 | 60-80 |
| 3 | 166424569696 | 20.0 | 20-40 |
| 4 | 166424569924 | 97.3 | 80-100 |
数据分析
对比分析
概念,无案例
基本统计分析
描述性统计分析,主要包括数据的集中趋势分析、数据的离散程度分析、数据的频数分布分析等,常用的统计指标有:计数、求和、平均数、
方差、标准差等
|
|
| id | area | sales | |
|---|---|---|---|
| 0 | 1 | 越秀区 | 1250 |
| 1 | 2 | 天河区 | 1253 |
| 2 | 3 | 番禺区 | 1280 |
| 3 | 4 | 南沙区 | 1260 |
| 4 | 5 | 增城区 | 1310 |
| 5 | 6 | 花都区 | 1190 |
| 6 | 7 | 海珠区 | 1288 |
| 7 | 8 | 黄埔区 | 1310 |
| 8 | 9 | 白云区 | 1220 |
| 9 | 10 | 从化市 | 1380 |
| 10 | 11 | 萝岗区 | 1256 |
| 11 | 12 | 荔湾区 | 1220 |
|
|
count 12.000000
mean 1268.083333
std 50.510950
min 1190.000000
25% 1242.500000
50% 1258.000000
75% 1293.500000
max 1380.000000
Name: sales, dtype: float64
获取百分位值
|
|
1250
分组分析
|
|
| id | reg_date | id_num | gender | birthday | age | |
|---|---|---|---|---|---|---|
| 0 | 100000 | 2011/1/1 | 15010219621116401I | 男 | 1962/11/16 | 52 |
| 1 | 100001 | 2011/1/1 | 45092319910527539E | 男 | 1991/5/27 | 23 |
| 2 | 100002 | 2011/1/1 | 35010319841017421J | 男 | 1984/10/17 | 30 |
| 3 | 100006 | 2011/1/1 | 37110219860824751B | 男 | 1986/8/24 | 28 |
| 4 | 100010 | 2011/1/1 | 53042219860714031J | 男 | 1986/7/14 | 28 |
|
|
gender
女 30.392493
男 26.979629
Name: age, dtype: float64
|
|
| gender | age | |
|---|---|---|
| 0 | 女 | 30.392493 |
| 1 | 男 | 26.979629 |
结构分析
在分组的基础上,计算各组成部分所占的比重
|
|
| id | reg_date | id_num | gender | birthday | age | |
|---|---|---|---|---|---|---|
| 0 | 100000 | 2011/1/1 | 15010219621116401I | 男 | 1962/11/16 | 52 |
| 1 | 100001 | 2011/1/1 | 45092319910527539E | 男 | 1991/5/27 | 23 |
| 2 | 100002 | 2011/1/1 | 35010319841017421J | 男 | 1984/10/17 | 30 |
| 3 | 100006 | 2011/1/1 | 37110219860824751B | 男 | 1986/8/24 | 28 |
| 4 | 100010 | 2011/1/1 | 53042219860714031J | 男 | 1986/7/14 | 28 |
|
|
gender
女 4316
男 54785
Name: id, dtype: int64
|
|
gender
女 0.073028
男 0.926972
Name: id, dtype: float64
分布分析
|
|
| 用户ID | 注册日期 | 身份证号码 | 性别 | 出生日期 | 年龄 | |
|---|---|---|---|---|---|---|
| 0 | 100000 | 2011/1/1 | 15010219621116401I | 男 | 1962/11/16 | 52 |
| 1 | 100001 | 2011/1/1 | 45092319910527539E | 男 | 1991/5/27 | 23 |
| 2 | 100002 | 2011/1/1 | 35010319841017421J | 男 | 1984/10/17 | 30 |
| 3 | 100006 | 2011/1/1 | 37110219860824751B | 男 | 1986/8/24 | 28 |
| 4 | 100010 | 2011/1/1 | 53042219860714031J | 男 | 1986/7/14 | 28 |
|
|
| 用户ID | 注册日期 | 身份证号码 | 性别 | 出生日期 | 年龄 | 年龄分层 | |
|---|---|---|---|---|---|---|---|
| 0 | 100000 | 2011/1/1 | 15010219621116401I | 男 | 1962/11/16 | 52 | (40, 100] |
| 1 | 100001 | 2011/1/1 | 45092319910527539E | 男 | 1991/5/27 | 23 | (20, 30] |
| 2 | 100002 | 2011/1/1 | 35010319841017421J | 男 | 1984/10/17 | 30 | (20, 30] |
| 3 | 100006 | 2011/1/1 | 37110219860824751B | 男 | 1986/8/24 | 28 | (20, 30] |
| 4 | 100010 | 2011/1/1 | 53042219860714031J | 男 | 1986/7/14 | 28 | (20, 30] |
|
|
年龄分层
(0, 20] 2061
(20, 30] 46858
(30, 40] 8729
(40, 100] 1453
Name: 用户ID, dtype: int64
|
|
年龄分层
(0, 20] 3.49%
(20, 30] 79.28%
(30, 40] 14.77%
(40, 100] 2.46%
Name: 用户ID, dtype: object
交叉分析
pandas 实现透视表功能
|
|
| 用户ID | 注册日期 | 身份证号码 | 性别 | 出生日期 | 年龄 | |
|---|---|---|---|---|---|---|
| 0 | 100000 | 2011/1/1 | 15010219621116401I | 男 | 1962/11/16 | 52 |
| 1 | 100001 | 2011/1/1 | 45092319910527539E | 男 | 1991/5/27 | 23 |
| 2 | 100002 | 2011/1/1 | 35010319841017421J | 男 | 1984/10/17 | 30 |
| 3 | 100006 | 2011/1/1 | 37110219860824751B | 男 | 1986/8/24 | 28 |
| 4 | 100010 | 2011/1/1 | 53042219860714031J | 男 | 1986/7/14 | 28 |
|
|
| 用户ID | 注册日期 | 身份证号码 | 性别 | 出生日期 | 年龄 | 年龄分层 | |
|---|---|---|---|---|---|---|---|
| 0 | 100000 | 2011/1/1 | 15010219621116401I | 男 | 1962/11/16 | 52 | (40, 100] |
| 1 | 100001 | 2011/1/1 | 45092319910527539E | 男 | 1991/5/27 | 23 | (20, 30] |
| 2 | 100002 | 2011/1/1 | 35010319841017421J | 男 | 1984/10/17 | 30 | (20, 30] |
| 3 | 100006 | 2011/1/1 | 37110219860824751B | 男 | 1986/8/24 | 28 | (20, 30] |
| 4 | 100010 | 2011/1/1 | 53042219860714031J | 男 | 1986/7/14 | 28 | (20, 30] |
|
|
| 性别 | 女 | 男 |
|---|---|---|
| 年龄分层 | ||
| (0, 20] | 111 | 1950 |
| (20, 30] | 2903 | 43955 |
| (30, 40] | 735 | 7994 |
| (40, 100] | 567 | 886 |
RFM 分析
|
|
| OrderID | CustomerID | DealDateTime | Sales | |
|---|---|---|---|---|
| 0 | 4529 | 34858 | 2014-05-14 | 807 |
| 1 | 4532 | 14597 | 2014-05-14 | 160 |
| 2 | 4533 | 24598 | 2014-05-14 | 418 |
| 3 | 4534 | 14600 | 2014-05-14 | 401 |
| 4 | 4535 | 24798 | 2014-05-14 | 234 |
|
|
dtype('<M8[ns]')
|
|
| OrderID | CustomerID | DealDateTime | Sales | DateDiff | |
|---|---|---|---|---|---|
| 0 | 4529 | 34858 | 2014-05-14 | 807 | 1959 |
| 1 | 4532 | 14597 | 2014-05-14 | 160 | 1959 |
| 2 | 4533 | 24598 | 2014-05-14 | 418 | 1959 |
| 3 | 4534 | 14600 | 2014-05-14 | 401 | 1959 |
| 4 | 4535 | 24798 | 2014-05-14 | 234 | 1959 |
|
|
| CustomerID | DateDiff | |
|---|---|---|
| 0 | 14568 | 1468 |
| 1 | 14569 | 1558 |
| 2 | 14570 | 1488 |
| 3 | 14571 | 1528 |
| 4 | 14572 | 1552 |
|
|
| CustomerID | OrderID | |
|---|---|---|
| 0 | 14568 | 15 |
| 1 | 14569 | 12 |
| 2 | 14570 | 15 |
| 3 | 14571 | 15 |
| 4 | 14572 | 8 |
|
|
| CustomerID | Sales | |
|---|---|---|
| 0 | 14568 | 6255 |
| 1 | 14569 | 5420 |
| 2 | 14570 | 8261 |
| 3 | 14571 | 8124 |
| 4 | 14572 | 3334 |
|
|
| CustomerID | RecencyAgg | FrequencyAgg | MonetaryAgg | |
|---|---|---|---|---|
| 0 | 14568 | 1468 | 15 | 6255 |
| 1 | 14569 | 1558 | 12 | 5420 |
| 2 | 14570 | 1488 | 15 | 8261 |
| 3 | 14571 | 1528 | 15 | 8124 |
| 4 | 14572 | 1552 | 8 | 3334 |
|
|
0.0 1460
0.2 1467
0.4 1479
0.6 1494
0.8 1513
1.0 1725
Name: RecencyAgg, dtype: int64
|
|
0 4
1 1
2 3
3 1
4 1
Name: RecencyAgg, dtype: category
Categories (5, int64): [5 < 4 < 3 < 2 < 1]
|
|
0 4
1 2
2 4
3 4
4 1
Name: FrequencyAgg, dtype: category
Categories (5, int64): [1 < 2 < 3 < 4 < 5]
|
|
0 3
1 2
2 4
3 4
4 1
Name: MonetaryAgg, dtype: category
Categories (5, int64): [1 < 2 < 3 < 4 < 5]
|
|
| CustomerID | RecencyAgg | FrequencyAgg | MonetaryAgg | R_S | F_S | M_S | |
|---|---|---|---|---|---|---|---|
| 0 | 14568 | 1468 | 15 | 6255 | 4 | 4 | 3 |
| 1 | 14569 | 1558 | 12 | 5420 | 1 | 2 | 2 |
| 2 | 14570 | 1488 | 15 | 8261 | 3 | 4 | 4 |
| 3 | 14571 | 1528 | 15 | 8124 | 1 | 4 | 4 |
| 4 | 14572 | 1552 | 8 | 3334 | 1 | 1 | 1 |
|
|
|
|
| CustomerID | RecencyAgg | FrequencyAgg | MonetaryAgg | R_S | F_S | M_S | RFM | |
|---|---|---|---|---|---|---|---|---|
| 0 | 14568 | 1468 | 15 | 6255 | 4 | 4 | 3 | 443 |
| 1 | 14569 | 1558 | 12 | 5420 | 1 | 2 | 2 | 122 |
| 2 | 14570 | 1488 | 15 | 8261 | 3 | 4 | 4 | 344 |
| 3 | 14571 | 1528 | 15 | 8124 | 1 | 4 | 4 | 144 |
| 4 | 14572 | 1552 | 8 | 3334 | 1 | 1 | 1 | 111 |
|
|
| CustomerID | RecencyAgg | FrequencyAgg | MonetaryAgg | R_S | F_S | M_S | RFM | level | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 14568 | 1468 | 15 | 6255 | 4 | 4 | 3 | 443 | 6 |
| 1 | 14569 | 1558 | 12 | 5420 | 1 | 2 | 2 | 122 | 1 |
| 2 | 14570 | 1488 | 15 | 8261 | 3 | 4 | 4 | 344 | 5 |
| 3 | 14571 | 1528 | 15 | 8124 | 1 | 4 | 4 | 144 | 2 |
| 4 | 14572 | 1552 | 8 | 3334 | 1 | 1 | 1 | 111 | 1 |
至此, RFM 分析的计算就完成了,求解得到的 level 和客户类型的对应关系如下
| R 值 | F 值 | M 值 | 客户类型 | level |
|---|---|---|---|---|
| 高 | 高 | 高 | 高价值客户 | 8 |
| 低 | 高 | 高 | 重点保持客户 | 7 |
| 高 | 低 | 高 | 重点发展客户 | 6 |
| 低 | 低 | 高 | 重点挽留客户 | 5 |
| 高 | 高 | 低 | 一般价值客户 | 4 |
| 低 | 高 | 低 | 一般保持客户 | 3 |
| 高 | 低 | 低 | 一般发展客户 | 2 |
| 低 | 低 | 低 | 潜在客户 | 1 |
最后我们看一下每个等级的人数
|
|
level
1 153
2 164
3 135
4 153
5 154
6 142
7 151
8 148
Name: CustomerID, dtype: int64
矩阵分析
|
|
| 号码 | 省份 | 手机品牌 | 通信品牌 | 手机操作系统 | 月消费(元) | 月流量(MB) | |
|---|---|---|---|---|---|---|---|
| 0 | 166547114238 | 河北 | HTC | 神州行 | Android | 298.9 | 318.6 |
| 1 | 166423353436 | 河南 | HTC | 神州行 | Android | 272.8 | 1385.9 |
| 2 | 166556915853 | 福建 | HTC | 神州行 | Android | 68.8 | 443.6 |
| 3 | 166434728749 | 湖南 | HTC | 神州行 | Android | 4.6 | 817.3 |
| 4 | 166544742252 | 北京 | HTC | 神州行 | Android | 113.2 | 837.4 |
|
|
| 省份 | 月消费(元) | |
|---|---|---|
| 0 | 上海 | 152.927748 |
| 1 | 云南 | 148.100832 |
| 2 | 内蒙古 | 154.427736 |
| 3 | 北京 | 148.895912 |
| 4 | 台湾 | 146.081277 |
|
|
| 省份 | 月流量(MB) | |
|---|---|---|
| 0 | 上海 | 1025.075667 |
| 1 | 云南 | 985.382830 |
| 2 | 内蒙古 | 997.965655 |
| 3 | 北京 | 1010.642977 |
| 4 | 台湾 | 1014.620346 |
|
|
| 省份 | 月消费(元) | 月流量(MB) | |
|---|---|---|---|
| 0 | 上海 | 152.927748 | 1025.075667 |
| 1 | 云南 | 148.100832 | 985.382830 |
| 2 | 内蒙古 | 154.427736 | 997.965655 |
| 3 | 北京 | 148.895912 | 1010.642977 |
| 4 | 台湾 | 146.081277 | 1014.620346 |
|
|
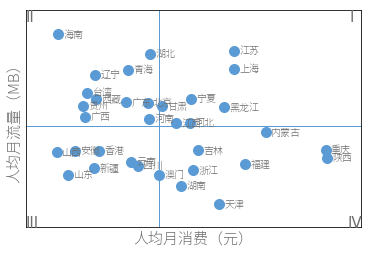
相关分析
研究的是两个变量之间的相互关系,计算相关系数
|
|
| 小区ID | 人口 | 平均收入 | 文盲率 | 超市购物率 | 网上购物率 | 本科毕业率 | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 3615 | 3624 | 2.1 | 15.1 | 84.9 | 41.3 |
| 1 | 2 | 365 | 6315 | 1.5 | 11.3 | 88.7 | 66.7 |
| 2 | 3 | 2212 | 4530 | 1.8 | 7.8 | 92.2 | 58.1 |
| 3 | 4 | 2110 | 3378 | 1.9 | 10.1 | 89.9 | 39.9 |
| 4 | 5 | 21198 | 5114 | 1.1 | 10.3 | 89.7 | 62.6 |
|
|
0.10762237339473261
|
|
| 超市购物率 | 网上购物率 | 文盲率 | 人口 | |
|---|---|---|---|---|
| 超市购物率 | 1.000000 | -1.000000 | 0.702975 | 0.343643 |
| 网上购物率 | -1.000000 | 1.000000 | -0.702975 | -0.343643 |
| 文盲率 | 0.702975 | -0.702975 | 1.000000 | 0.107622 |
| 人口 | 0.343643 | -0.343643 | 0.107622 | 1.000000 |
回归分析
简单线性回归分析
一元线性回归Y = a + bX + e e 为误差
|
|
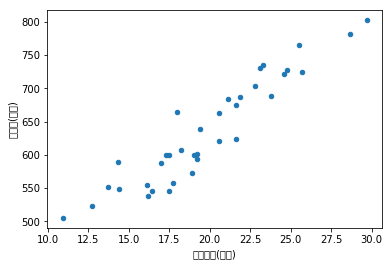
| 月份 | 广告费用(万元) | 销售额(万元) | |
|---|---|---|---|
| 0 | 201601 | 29.7 | 802.4 |
| 1 | 201602 | 25.7 | 725.0 |
| 2 | 201603 | 20.6 | 620.5 |
| 3 | 201604 | 17.0 | 587.0 |
| 4 | 201605 | 10.9 | 505.0 |
1. 根据预测目标,确定自变量因变量
|
|
2. 绘制散点图,确定回归模型类型
|
|
<matplotlib.axes._subplots.AxesSubplot at 0x11942fe10>
|
|
0.9377748050928367
3. 估计模型参数,建立回归模型
从散点图中可以看出两者有明显的线性关系,但是这些数据点不在一条直线上,只能尽可能拟合出一条直线,使得尽可能多的数据点落在
或者更加靠近这条拟合出来的直线上,也就是让它们拟合的误差尽量小,最小二乘法就是一个较好的计算方法。
|
|
(array([[17.31989665]]), array([291.90315808]))
4. 对回归模型进行检验
精度,就是用来表示点和回归模型的拟合程度的指标,一般使用判定系数 R^2 来度量回归模型拟合精度,也称拟合优度或决定系数,在
简单线性回归模型中,它的值等于 y 值和模型计算出来的 y’ 值的相关系数 R 的平方,用来表示拟合得到的模型能够解释因变量变化的百分比
,R^2 越接近 1, 表示回归模型拟合效果越好。
|
|
0.8794215850669082
可以看到拟合效果还是非常不错的
5. 利用回归模型进行预测
|
|
array([[638.30109101]])
多重线性回归分析
就是多个自变量的线性回归,分析方法和简单线性相似
|
|
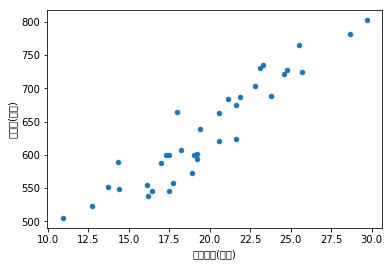
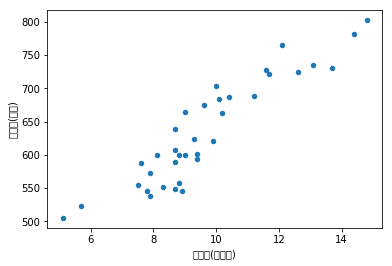
| 月份 | 广告费用(万元) | 客流量(万人次) | 销售额(万元) | |
|---|---|---|---|---|
| 0 | 201601 | 29.7 | 14.8 | 802.4 |
| 1 | 201602 | 25.7 | 12.6 | 725.0 |
| 2 | 201603 | 20.6 | 9.9 | 620.5 |
| 3 | 201604 | 17.0 | 7.6 | 587.0 |
| 4 | 201605 | 10.9 | 5.1 | 505.0 |
根据预测目标,确定自变量和因变量
|
|
绘制散点图,确定回归模型类型
|
|
<matplotlib.axes._subplots.AxesSubplot at 0x125e2fe10>
|
|
0.9377748050928367
|
|
<matplotlib.axes._subplots.AxesSubplot at 0x12654ac18>
|
|
0.9213105695705346
估计模型参数,建立线性回归模型
|
|
(array([[10.80453641, 13.97256004]]), array([285.60371828]))
对回归模型进行检验
|
|
0.9026563046475117
拟合效果非常不错
利用回归模型进行预测
|
|
| 广告费 | 客流量 | |
|---|---|---|
| 0 | 20 | 5 |
|
|
array([[571.55724658]])
数据可视化
散点图
|
|
| 日期 | 购买用户数 | 广告费用 | 促销 | 渠道数 | |
|---|---|---|---|---|---|
| 0 | 2014/1/1 | 2496 | 9.14 | 否 | 6 |
| 1 | 2014/1/2 | 2513 | 9.47 | 否 | 8 |
| 2 | 2014/1/3 | 2228 | 6.31 | 是 | 4 |
| 3 | 2014/1/4 | 2336 | 6.41 | 否 | 2 |
| 4 | 2014/1/5 | 2508 | 9.05 | 是 | 5 |
|
|
<matplotlib.collections.PathCollection at 0x12652dd68>
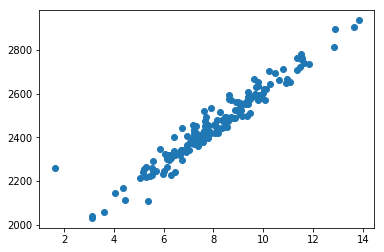
颜色设置
|
|
<matplotlib.collections.PathCollection at 0x129083080>
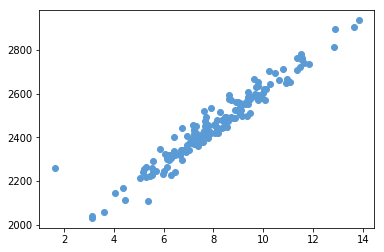
坐标轴设置
|
|
Text(0, 0.5, '购买用户数')

|
|
(array([0. , 0.2, 0.4, 0.6, 0.8, 1. ]), <a list of 6 Text yticklabel objects>)

散点样式设置
|
|
<matplotlib.collections.PathCollection at 0x1291f04a8>
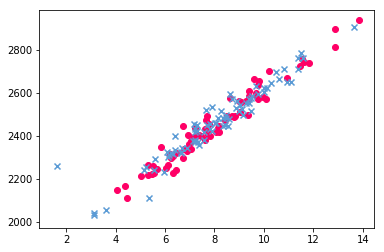
添加图例
|
|
<matplotlib.legend.Legend at 0x129474a90>

完整绘图示例
|
|
<matplotlib.legend.Legend at 0x12951bc88>
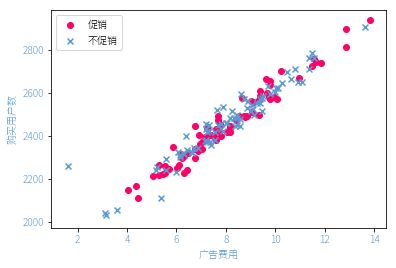
矩阵图
参考之前的矩阵分析绘图部分
折线图
|
|
| id | reg_date | id_num | gender | birthday | |
|---|---|---|---|---|---|
| 0 | 109899 | 2011-02-01 | 35042519920219007J | 男 | 1992/2/19 |
| 1 | 109903 | 2011-02-01 | 43048119891223411D | 男 | 1989/12/23 |
| 2 | 109904 | 2011-02-01 | 42010219880201313H | 男 | 1988/2/1 |
| 3 | 109905 | 2011-02-01 | 44030619840213001E | 男 | 1984/2/13 |
| 4 | 109906 | 2011-02-01 | 43070219870502103H | 男 | 1987/5/2 |
|
|
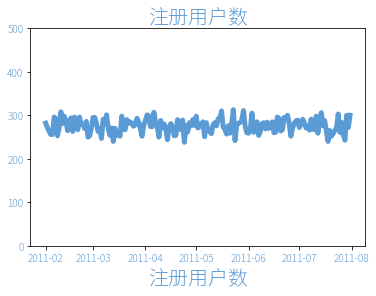
| 注册日期 | 注册用户数 | |
|---|---|---|
| 0 | 2011-02-01 | 282 |
| 1 | 2011-02-02 | 272 |
| 2 | 2011-02-03 | 264 |
| 3 | 2011-02-04 | 256 |
| 4 | 2011-02-05 | 256 |
|
|
[<matplotlib.lines.Line2D at 0x12a557438>]
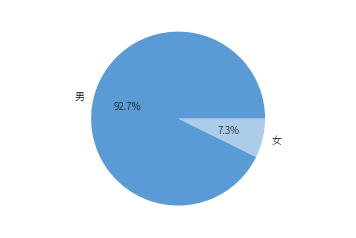
饼图
|
|
|
|
男 54785
女 4316
dtype: int64
|
|
([<matplotlib.patches.Wedge at 0x1484e9748>,
<matplotlib.patches.Wedge at 0x1484e9e48>],
[Text(-1.0711775990020538, 0.25015705346081196, '男'),
Text(1.0711775814360058, -0.2501571286789748, '女')],
[Text(-0.5842786903647565, 0.1364493018877156, '92.7%'),
Text(0.5842786807832758, -0.13644934291580443, '7.3%')])
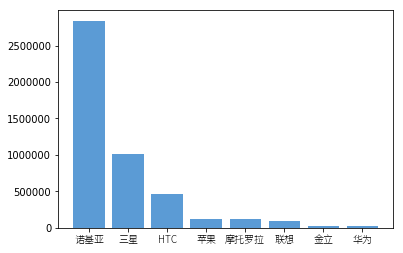
柱状图
|
|
| 号码 | 省份 | 手机品牌 | 通信品牌 | 手机操作系统 | 月消费(元) | 月流量(MB) | |
|---|---|---|---|---|---|---|---|
| 0 | 166547114238 | 河北 | HTC | 神州行 | Android | 298.9 | 318.6 |
| 1 | 166423353436 | 河南 | HTC | 神州行 | Android | 272.8 | 1385.9 |
| 2 | 166556915853 | 福建 | HTC | 神州行 | Android | 68.8 | 443.6 |
| 3 | 166434728749 | 湖南 | HTC | 神州行 | Android | 4.6 | 817.3 |
| 4 | 166544742252 | 北京 | HTC | 神州行 | Android | 113.2 | 837.4 |
|
|
| 手机品牌 | 月消费(元) | |
|---|---|---|
| 0 | HTC | 458171.6 |
| 1 | 三星 | 1009290.8 |
| 2 | 华为 | 25696.0 |
| 3 | 摩托罗拉 | 117623.1 |
| 4 | 联想 | 89443.7 |
|
|
([<matplotlib.axis.XTick at 0x148504470>,
<matplotlib.axis.XTick at 0x129caaa20>,
<matplotlib.axis.XTick at 0x129caada0>,
<matplotlib.axis.XTick at 0x129cce630>,
<matplotlib.axis.XTick at 0x1484fcac8>,
<matplotlib.axis.XTick at 0x129cce828>,
<matplotlib.axis.XTick at 0x129cd1390>,
<matplotlib.axis.XTick at 0x129cd4198>],
<a list of 8 Text xticklabel objects>)
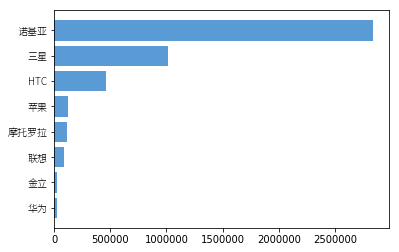
条形图
|
|
([<matplotlib.axis.YTick at 0x14872aeb8>,
<matplotlib.axis.YTick at 0x14872a828>,
<matplotlib.axis.YTick at 0x14873beb8>,
<matplotlib.axis.YTick at 0x148761940>,
<matplotlib.axis.YTick at 0x148761e10>,
<matplotlib.axis.YTick at 0x1487cc320>,
<matplotlib.axis.YTick at 0x1487cc7f0>,
<matplotlib.axis.YTick at 0x148761a20>],
<a list of 8 Text yticklabel objects>)
|
