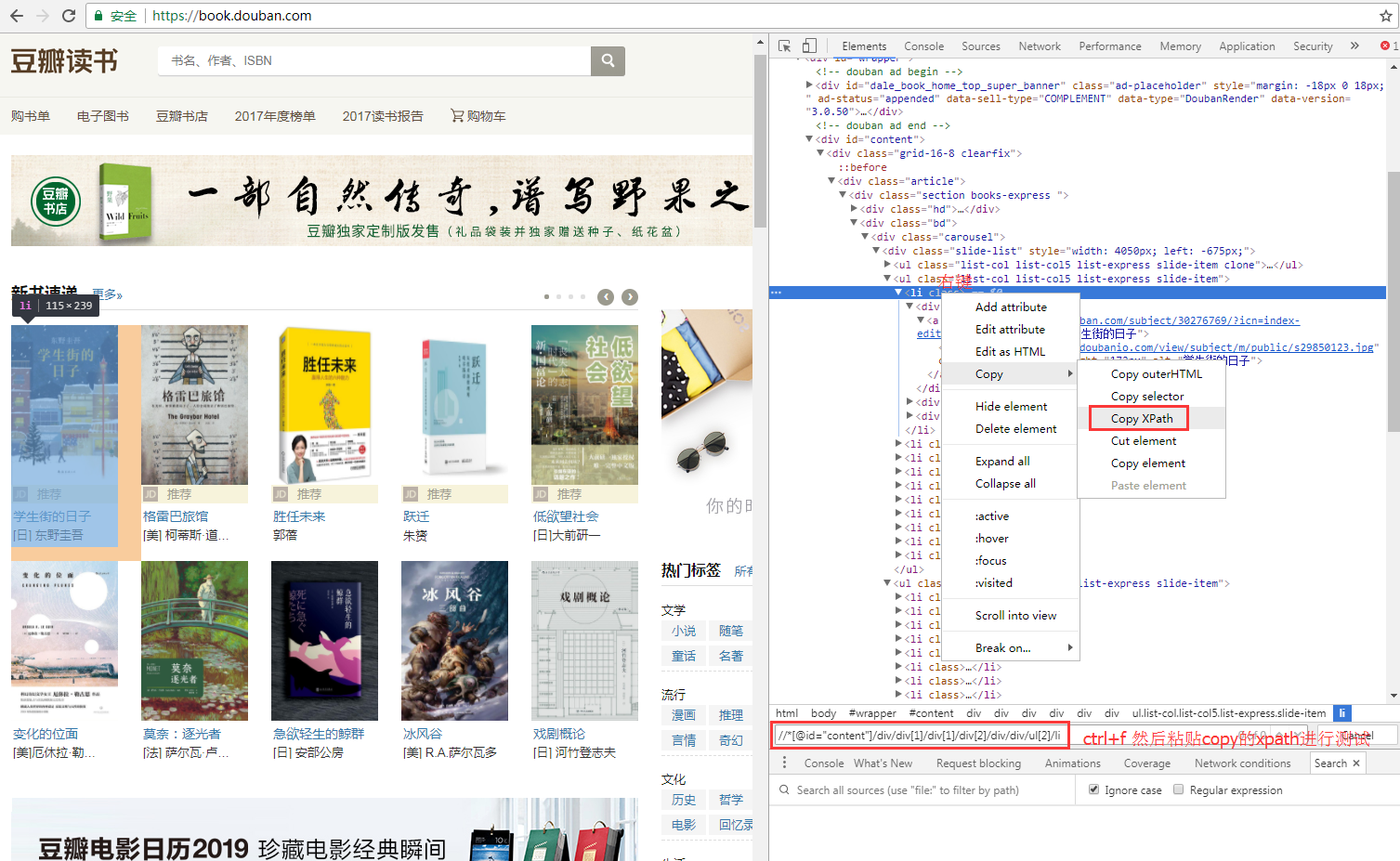
爬虫-xpath 发表于 2018-10-23 | 更新于 2019-04-11 | 分类于 python , xpath | 阅读次数: 语法w3c文档看过之后可以通过后面的 应用 部分理解一下 获得 xpath 路径通过chrome浏览器可以右键来查看 应用这里直接用的scrapy自带的解析器进行举例解析 12345678910111213141516171819202122232425262728293031323334353637383940#!/usr/bin/env python# -*- coding:utf-8 -*-from scrapy.selector import Selectorfrom scrapy.http import HtmlResponsehtml = """<!DOCTYPE html><html> <head lang="en"> <meta charset="UTF-8"> <title></title> </head> <body> <ul> <li class="item-"><a id='i1' href="link.html" class='ding'>first item</a></li> <li class="item-0"><a id='i2' href="llink.html" class='ding'>first item</a></li> <li class="item-1"><a href="llink2.html">second item<span>vv</span></a></li> </ul> <div><a href="llink2.html">second item</a></div> <div><a href="llink2.html">10</a></div> <div> <div class='test_div' >test div</div> <ul> <li class="item-55"><a id='i55' href="link.html" class='ding'>first item</a></li> <li class="item-66"><a id='i66' href="llink.html" class='ding'>first item</a></li> <li class="item-77"><a href="llink2.html">second item<span>vv</span></a></li> </ul> </div> </body> <ul> <li class="item-5"><a id='i5' href="link.html" class='ding'>first item</a></li> <li class="item-6"><a id='i6' href="llink.html" class='ding'>first item</a></li> <li class="item-7"><a href="llink2.html">second item<span>vv</span></a></li> </ul></html>"""# 构造response对象response = HtmlResponse(url='', body=html, encoding='utf-8')selector = Selector(response=response) 从根搜索12345# // 从根开始搜索# 获取所有a标签temp = selector.xpath('//a')# 搜索所有符合 div/div 的temp = selector.xpath('//div/div') 获取子标签123# 获取子标签# 获取不到,因为a标签不是html的子标签temp = selector.xpath('a') 相对父标签和绝对路径123456789101112131415161718192021222324# 相对位置绝对位置# 获取第一个body标签, 下面从body标签开始找ul标签x = selector.xpath('body')[0]# ./ul 相对标签的子标签ultemp = x.xpath('./ul')# print(temp)# 同上 相对于标签的子标签ultemp = x.xpath('ul')# print(temp)# .//ul 相对父标签(body)的所有子代ultemp = x.xpath('.//ul')# //ul 这个就不是相对的了,还是从根开始查找temp = x.xpath('//ul')# print(temp)# 相对temp = selector.xpath('body/div')[0].xpath('.//li')# print(temp)# 绝对 还是搜所有的,不依赖父标签temp = selector.xpath('body/div')[0].xpath('//li') 获取标签后代或子标签12345678# 获取body的子标签ultemp = selector.xpath('body/ul')# 获取body的所有后代标签ultemp = selector.xpath('body//ul')# 获取body的后代标签litemp = selector.xpath('body//li')# []空,li不是body的子标签temp = selector.xpath('body/li') 获取当前标签的父标签12# 获取body的父标签temp = selector.xpath('body')[0].xpath('..') 根据标签属性或者值进行搜索1234567891011121314# 获取包含class属性的标签temp = selector.xpath('//@class')# 获取属性class=item-0的标签temp = selector.xpath('//@class=item-0')# 拥有id属性的a标签temp = selector.xpath('body//a[@id]')# 标签a id属性为i1temp = selector.xpath('body//a[@id=i1]')# 标签div下a标签值为 second item 的div标签temp = selector.xpath('body//div[a="second item"]')# 获取属性class为ding并且属性href为llink.html的a标签temp = selector.xpath('//a[@class="ding"][@href="llink.html"]') 其他不常用1234567891011121314151617181920212223242526272829303132333435363738394041424344# 获取body的后代第一个li标签temp = selector.xpath('body//li[1]')# 获取body的后代最后一个li标签temp = selector.xpath('body//li[last()]')# 获取body的后代倒数第二个li标签temp = selector.xpath('body//li[last()-1]')# 获取body的后代前两个li标签temp = selector.xpath('body//li[position() < 3]')# 标签div下a标签值小于30的div标签temp = selector.xpath('body//div[a < 30]')# 匹配任何节点temp = selector.xpath('//*')# 匹配当前节点任何子节点temp = selector.xpath('*')# 匹配当前节点任何子节点包含属性的节点temp = selector.xpath('@*')# 匹配任何包含了属性的节点temp = selector.xpath('//@*')# 获取body子元素中的ul标签temp = selector.xpath('body/child::ul')# 获取body标签的父标签temp = selector.xpath('body/parent::*')# 获取body标签的祖先标签temp = selector.xpath('body/ancestor::*')# 获取body标签的祖先标签包含自己temp = selector.xpath('body/ancestor-or-self::*')# 获取body标签的后代标签temp = selector.xpath('body/descendant::*')# 获取body标签的后代标签为a的a标签temp = selector.xpath('body/descendant::a')# 获取body标签的后代标签包含自己temp = selector.xpath('body/descendant-or-self::*')# 获取body标签的同级标签temp = selector.xpath('body/preceding-sibling::*')# 获取class为item-0的li标签的下一个同级标签temp = selector.xpath('//li[@class="item-0"]/following-sibling::*')# 获取class为item-0的li标签后面的所有标签temp = selector.xpath('//li[@class="item-0"]/following::*')# 获取class为item-0的li标签前面的所有标签temp = selector.xpath('//li[@class="item-0"]/preceding::*')# 获取所有li节点的所有属性temp = selector.xpath('//li/attribute::*') 正则匹配属性值123456789101112# 获取属性href包含link的a标签temp = selector.xpath('//a[contains(@href, "link")]')# 获取属性href以llin开头的a标签temp = selector.xpath('//a[starts-with(@href, "llin")]')# 正则匹配 id属性符合正则的a标签temp = selector.xpath('//a[re:test(@id, "i\d+")]')# 正则匹配 id属性符合正则的a标签 获取标签内容,并转换成正常的列表temp = selector.xpath('//a[re:test(@id, "i\d+")]/text()').extract()# 正则匹配 id属性符合正则的a标签 获取标签href属性值,并转换成正常的列表temp = selector.xpath('//a[re:test(@id, "i\d+")]/@href').extract()# 正则匹配 id属性符合正则的a标签 获取标签href属性值,获取第一个值temp = selector.xpath('//a[re:test(@id, "i\d+")]/@href').extract_first() 获取标签内容或者属性值1234567# 获取标签内容,并转换成正常的列表temp = selector.xpath('//div/div/text()').extract()# 获取标签内容,获取列表中的第一个值temp = selector.xpath('//div/div/text()').extract_first()# 获取标签属性值,并转换成正常的列表temp = selector.xpath('//div/div/@class').extract()# print(temp) 欢迎您扫一扫上面的微信公众号,订阅我的博客! 坚持原创技术分享,您的支持将鼓励我继续创作! 打赏 微信支付 支付宝