数据库相关
创建数据库
|
|
查看mysql中的所有字符编码名(字符集)
|
|
查看所有的排序规则名
|
|
创建数据库示例
|
|
修改数据库
|
|
备份数据库
不需要进入mysql服务执行
备份示例
|
|
恢复数据库
创建需要导入的数据库
1CREATE DATABASE test CHARSET utf8;将数据还原 注意:先要创建还原的数据库test
1mysql -hlocalhost -uroot -p test < /Users/echo-ding/Documents/ding/test.sql
删除数据库
|
|
删除表
|
|
查看表结构
|
|
查看表的创建语句
|
|
复制表结构
|
|
清空一张表
|
|
相当于删除一张表重新创建
添加列
|
|
更改表名
|
|
创建表
|
|
|
|
字段属性
primary key (fields1[,fields2,……]) :设定主键,每个表需要(必须,只能)有一个,字段值不能重复。可以多个字段共同组成一个主键。unique key (fields1[,fields2,……]) :用于设定该字段的值,在这个表中,不可以重复(即是唯一的)key (fields1[,fields2,……]) : 普通索引,仅仅是建立了索引fulltext key (fields1[,fields2,……]) :全文索引,目前对中文支持不好foreign (fields1[,fields2,……]) references 其他表(fields1[,fields2,……]) : 设定外键,附加外键索引和外键约束auto_increment :用于设定一个字段值(整型的)的自动增长(自增),而且,它设定后还必须同时设定在一个字段为一个“key”(比如:priamry key 或 unique key)not null: 用于设定一个字段的值不能为空值(null)——如果不设定,则就是可为空值;非空约束
null是一种类型,比较时,只能用专门的is null 和 is not null来比较.default XX值:用于设定某个字段的值,在插入数据的时候如果没有给值,就使用该默认值;comment ‘说明文字’:就是一个说明字段含义的文字,备注
修改表的字段/属性/索引
|
|
查
|
|
where字句
算数运算符
比较运算符
逻辑运算符
is运算符
between运算符
in运算符
like运算符——模糊查找
group by 字句 —分组
group by 根据 select 查询语句查询出的结果进行分组
用法
- group by子句是用于将“前面”取得的数据,按某种标准(依据)——也就是字段——来进行分组的。分组,基本上就是,按给定字段的值,相同的值,分在相同的组中,不同的值分在不同的组中。
- asc表示分组后,按组的值的大小正序排列,desc是倒序——默认是正序,可以不写。
- 一个最重要的理解(观念):分组之后的结果,也是一行一行数据,只是每一行代表“一组”
特别注意:
分组之后,结果行中的数据,都只能出现“组信息”——描述该组的“应有信息”。
具体来说,对于分组查询的结果数据(select子句部分),只能出现如下几类数据:
1, 分组依据字段;
2, 原始字段信息中的数字类型的最大值,最小值,平均值,总和值;
max(字段):获得该字段的在组中的最大值;
min(字段):获得该字段的在组中的最小值;
avg(字段):获得该字段的在组中的平均值;
sum(字段):获得该字段的在组中的总和值;
3, 每一组中所包含的原始数据行的行数,获得方式为:count(*)
|
|
如果没有使用聚合函数直接使用字段,默认显示该字段的第一个值
having字句
having条件语句和where条件语句的区别,使用的目标不一样,where是对原始数据(表数据)进行的筛选行为,而having是对group by分组后形成的数据进行的筛选(可以把group by分组后的结果当成一张表),having能用的筛选条件只能是select子句中出现的字段
用法:
例子:
order by排序子句
对查询结果进行排序
用法:
按照字段名进行顺序或倒序排序,多个字段名时,先按照第一个字段名排序,再按照第二个字段名进行排序……
limit 子句
用法:
DISTINCT关键字
合并查询记过重复行
合并查询字段结果的重复的行
子查询
就是通过把查询语句的值作为条件进行查询的
子查询方便,但是性能原因略低,一般也会回用,省略
执行子查询时,MYSQL需要创建临时表,查询完毕后再删除这些临时表,所以,子查询的速度会受到一定的影响,这里多了一个创建和销毁临时表的过程。
union 子查询
合并两个查询的结果
用法:
说明:
- distinct | all用于设定是否消除重复行,默认不写就是distinct,表示会消除重复行;
- order by子句和limit子句,是对整个联合之后的数据结果进行排序和数量限定;
- 这两个select语句,要求字段数量必须一致,对应字段类型最好一致;
- 联合查询的结果数据中,字段名以第一个select语句中的字段名为准;
- 第一个select语句中的字段名如果有别名,则后续的order by子句就必须使用该别名;
将两个“字段一致”的查询语句所查询到的结果以“纵向堆叠”的方式合并到一起,成为一个新的结果集。
结果集的行数是两个独立select查询语句的结果行数的和
连表查询
用法:
常用的两个连表查询
内连接 inner join
结果:是在交叉连接的结果(两表之间做全相乘的结果)中筛选出符合 on 后面条件的
也是左连接和右连接的交集
左(外)连接 left [outer] join
假设A表在左,不动。B表在A表的右侧滑动,A表和B表通过一个关系(条件)来筛选B表的行,
如果符合条件,则B表取出对应的行与A表对应的行组成新的一行数据,添加到结果集中,形成的结果集可以看成一张表,设为C,形成的结果集(表c)最少的行数为左边表(表A)的行数。
也可以理解为 内连接的结果
添加上没有匹配上的表A的没有匹配上数据的行(右边部分填充null)
此时,可以对C表进行查询操作,where ,group,having,order by,limit依旧可以使用
增
|
|
插入数据
删
|
|
改
|
|
列类型
整数类型
| 名称 | 字节 | 最小值(带符号/不带符号) | 最大值(带符号/不带符号) |
|---|---|---|---|
| tinyint | 1 | -128/0 | 127/255 |
| smallint | 2 | -32768/0 | …… |
| mediumint | 3 | -8388608/0 | …… |
| int | 4 | -2147483648/0 | …… |
| bigint | 8 | -9223372036854775808/0 | …… |
1字节(byte)有8位(bit),当显示负数的时候需要占用首位进行表示,所以表示数值的只有7位
使用形式
类型名 [M(长度)] [unsigned] [zerofill]
- 其中M表示“显示长度”,其需与zerofill结合使用才有效,即不够该长度的会自动左侧补0,当然如果超出也不影响。长度,就是用来设定要显示的长度位数(数字个数)
- unsigned表示“无符号数”,表示其中的数值是“非负”数字
- 如果设置了zerofill,则自动也就表示同时具备了unsigned修饰
- 如果设置了zerofill但没有设定长度M,则其会默认将所有数的左边补0到该类型的最大位数
小数类型
| 类型 | 名称 | 字节 | 精度 |
|---|---|---|---|
| 浮点型 | |||
| 单精度 | float(m,d) | 4 | 6-7位 |
| 双精度 | double(m,d) | 8 | 15位 |
| 定点型 | |||
| decimal(m,d) | 如果M>D,为M+2否则为D+2 | 总精度65位/小数部分精度30位 |
m叫“精度”,代表“总位数”, d表示“标度”,代表小数位
浮点型的小数,内部是二进制形式,所以很可能是非精确的,基本多有语言都有的毛病
字符串类型
| 类型 | 大小(字节) | 用途 |
|---|---|---|
| CHAR | 0-255(字符) | 固定长度 |
| VARCHAR | 0-65535 | 变化长度 |
| TEXT | 0-65535 | 长文本数据 |
| enum | 最多65535选项 | 单选类型 |
| set | 最多64选项 | 多选类型 |
- char(m)类型:
定长字符串,m表示设定的字符长度,存储内容和编码格式无关,其存储的时候,就是该长度——不够就会自动补空格填满;
最大可设定为255,表示可存储255个 字符; varchar(m)类型:
变长字符串,m表示设定的字节数长度,存储内容和编码格式有关,是可存储的最大长度,实际存储长度可以小于该长度;
该类型存储的时候,还需要在字段内的最前面额外存储该字段的实际长度;
最大可设定为65533,表示最大可存储65533个 字节;
因为考虑因素:一行 的总的存储空间限制是65535 字节,
但有考虑字符编码的问题,又会出现:
如果存储的是纯英文字符,则实际最多可存储65533个字符;
如果存储的是纯gbk的中文字符,则实际最多可存储的是65533/2个字符;
如果存储的是纯utf8的中文字符,则实际最多可存储的是65533/3个字符;text类型:
它通常用于存储“大文本”,因为其可存储65535个字节,并且, 不受行存储空间的限制;不能设置默认值
varchar和text存储结构上是有区别的,text是单独存储的,不受行存储空间限制;对于大文本的字段最好分拆成单独一个表
从存储上来讲大于255的varchar可以说是转换成了text.这也是为什么varchar大于65535了会转成mediumtext
字段的额外开销
- varchar 小于255byte 1byte overhead
varchar 大于255byte 2byte overhead
tinytext 0-255 1 byte overhead
- text 0-65535 byte 2 byte overhead
mediumtext 0-16M 3 byte overhead
longtext 0-4Gb 4byte overhead
备注 overhead是指需要几个字节用于记录该字段的实际长度。
在固定的长度下char类型比varchar占用空间更少,并且由于char是固定长度,所以更利于搜索速度
.
enum类型:
用于存储若干个“可选项之一”的一种字符类型。
通常,是在字段定义时,预先设定多个选项,而且是作为单选项,实际存储数据的时候,就可以选择其中一个存入数据库。
它适合于存储在网页中的“单选项”数据,比如:单选按钮,下拉列表选项值等等;
形式:
enum(‘单选项1’, ‘单选项2’, ‘单选项3’, ……. ); //最多65535个。
说明:
这些选项,在系统内部,实际对应的是如下这些数字值:1, 2, 3, 4, 5, 6, ….set类型:
用于存储若干个“多选项”的一种字符类型。
通常,是在字段定义时,预先设定多个选项,而且是作为多选项,实际存储数据的时候,就可以选择其中若干个选项值存入数据库。
它适合于存储在网页中的“多选项”数据,比如:多选按钮;
形式:
set(‘多选项1’, ‘多选项2’, ‘多选项3’, ……. ); //最多64个。
说明:
这些选项,在系统内部,实际对应的是如下这些数字值:1, 2, 4, 8, 16, …. 3表示选择类1和2
时间类型
| 类型 | 大小(字节) | 范围 |
|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 |
| TIME | 3 | -838:59:59/838:59:59 |
| YEAR | 1 | 1901/2155 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 |
| TIMESTAMP | 8 | 1970-01-01 00:00:00/2037 年某时 |
timestamp和datetime基本相似
timestamp额外特性:
用于记录一个“当前时间”的精确的时间戳——也就是某个时刻的对应整数值;
该整数值,表示,从1970年1月1日0时0分0秒开始算起到该时候所经历的秒数;
而且,其有如下特征:
该字段的值,会在一个表的某行数据执行insert或update的时候,自动获取该时刻的时间戳值;
显示格式 YYYY-MM-DD HH:MM:SS
特性:不用赋值,该列会为自己赋当前的具体时间 ,但是要添加not null属性
注意:
作为时间日期类型的数据,如果是在代码中插入一个具体的字面数据值,则需要用单引号引起来——跟字符类型一样。
用户管理
添加用户
mysql中的用户数据,都存储在mysql的系统数据库“mysql”中的user表中
“允许登录的网络位置”表示,该用户,在输入正确的用户名和密码的同时,也必须在“指定”的位置来登录该服务器。位置就是网络地址,通常是ip地址;其中,localhost表示只允许在本机(本地)登录。
如果想远程登录的话,将”localhost”改为”%”,表示在任何一台电脑上都可以登录。也可以指定某台机器可以远程登录。
添加权限
|
|
说明:
- 权限名,就是上述那些单词或单词组合,比如:select,insert,delete,等等;
- 某下级单位,指的是,一个数据库中的下级可操作对象,比如表,视图,
2.1 举例:shuangyuan.join1, 或者shuangyuan.tab1, mysql.user
2.2 特例1:*.*表示整个系统中的所有数据库的所有下级单位;
2.3 特例2:某库名.*,表示该指定数据库的所有下级单位; - identified 用于给现有的该用户改密码。如果不改密码,就可以不写;
- 该grant语句,还可以给“不存在的用户”进行授权,此时实际上,会同时创建该用户。如果是这种情况,则此时,identified部分就不可以省略,而是必须给出密码;
例子:
权限列表:
取消权限
|
|
数据文件
以引擎为 MyISAM 为例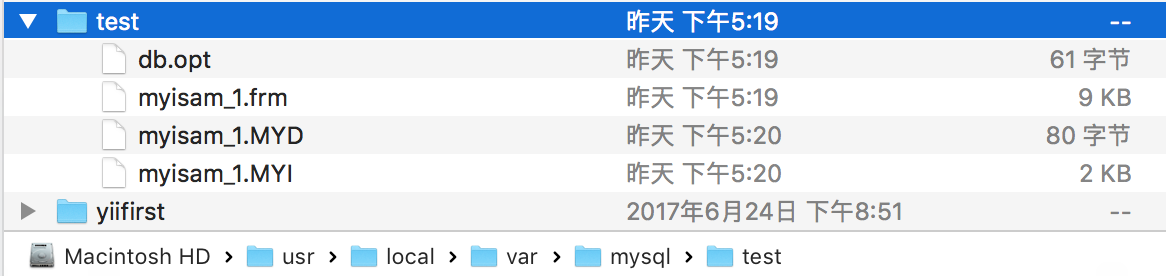
test 数据库文件夹
db.opt 数据库文件
myisam_1.frm 表结构文件
myisam_1.MYD 数据文件
myisam_1.MYI 索引文件
